Українська студентка створила ШІ-модель, що виявляє російську пропаганду у вікіпедії
Випускниця Українського католицького університету (УКУ) Вікторія Маковська створила модель, яка допомагає виявляти російські маніпуляції у Wikipedia, навіть коли вони маскуються під нейтральні формулювання.

Про це пише Mind.
Як зазначається, наразі автоматизована модерація Wikipedia не спрямована безпосередньо на виявлення тонких текстових маніпуляцій. Вона фокусується переважно на очевидних проявах вандалізму, таких, як повторювані вставки тексту капслоком, особисті образи, жарти, а також перевірка наявності чи релевантності джерел.
Тому у фокусі розробки випускниці УКУ Вікторії Маковської став машинний аналіз спроб поширення дезінформації, а не остаточних версій статей. Її дипломний проєкт на цю тему – «Вандалізм чи маніпуляція знаннями? Виявлення наративів у редагуваннях Wikipedia» – визнано одним із найкращих проєктів випускників УКУ 2025 року. Він базується на ML-моделі (machine learning – машинне навчання).
Читайте також: Як боротися з дезінформацією і захищати демократію. Лекція Пітера Померанцева
За словами Вікторії, модель поки що працює з енциклопедичними текстами, але її підхід має потенціал для подальшого застосування – наприклад, у телеграм-каналах чи новинних стрічках, де пропаганда часто має вигляд просто «альтернативної думки». Інакше кажучи, основне завдання розробки – навчити ШІ бачити там, де людина не помічає нічого підозрілого.
Вікіпедію часто використовують як джерело даних для тренування великих мовних моделей. Тому в разі потрапляння туди викривленої інформації вона й надалі може просочуватися навіть у чат-боти, створені на основі цих моделей. Такий підхід уже має назву LLM grooming, і російська пропаганда активно використовує цей інструмент проти України.
Тому метою проєкту було створити систему, яка зможе аналізувати також дублікати Wikipedia (зокрема, Ru Wikipedia Fork) і виявляти в них ознаки російської пропаганди.
Як навчали модель
Модель донавчали на власному датасеті (структурованому наборі даних), що містив приклади пропагандистських і нейтральних текстів із Вікіпедії. Вікторія створювала віртуальне середовище, де запускалися скрипти для аналізу та навчання. Система не «шукає» фейки самостійно в енциклопедії. Вона працює за іншим принципом: на вхід подається текстова ревізія (revision), тобто конкретна зміна, яку хтось хоче внести до статті у Вікіпедії; модель аналізує цю зміну як фрагмент тексту й видає оціночний бал (score) від 0 до 1 – наскільки ймовірно, що ця правка є деструктивною.
Для аналізу Вікторія зібрала всі зміни в українській і російській Вікіпедії за 2022–2023 роки на основі попередньо визначеного списку статей. До вибірки увійшли як правки, які були погоджені модераторами, так і так званий вандалізм – редагування, що порушували правила платформи й були згодом скасовані.
Основну увагу було зосереджено на відхилених змінах, адже саме вони найчастіше містили маніпулятивні або шкідливі елементи. Таких редагувань було набагато менше, ніж звичайних, і це створило нерівномірний набір даних. У цій ситуації штучному інтелекту складніше навчитися помічати рідкісні випадки, бо їх просто недостатньо для повноцінного навчання. Щоб зменшити цей ризик, дослідниця застосувала техніки балансування й обрала альтернативні метрики, які дозволяють адекватно оцінити роботу моделі навіть у таких умовах.
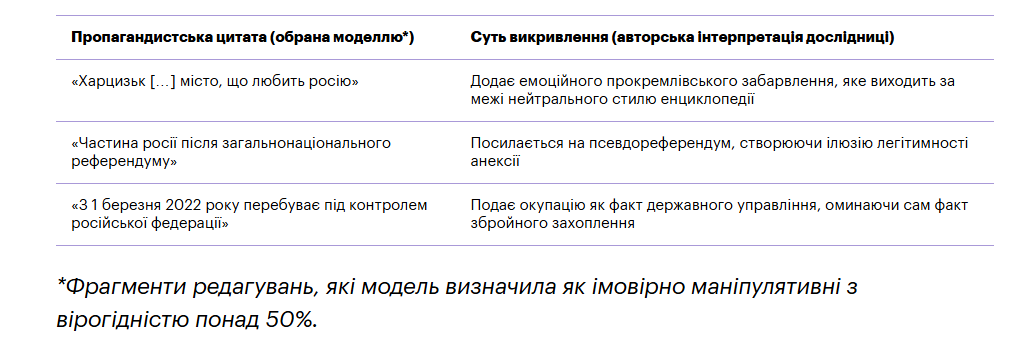
Також у дослідженні використовувався згаданий дзеркальний варіант російської Вікіпедії – RuWiki Fork. Що дало змогу бачити редагування, які були тільки там. Наприклад, якщо у статті про Маріуполь у RuWiki з’являвся текст, який виправдовує окупацію, а в основній Вікіпедії такого фрагмента не було – це сигнал, що відбулася підозріла правка. Саме подібні випадки стали основою для тренування моделі на виявлення потенційно шкідливих меседжів.
Читайте також: Росіяни пишуть свою енциклопедію: Рувікі, з якої викреслюють війну
За словами Вікторії, у результаті розробка була адаптована для виявлення пропагандистських формулювань, які вважаються підвидом вандалізму у Wikipedia: спотворення фактів, ідеологічно забарвлена лексика та інші мовні індикатори впливу. Модель демонструє стійку здатність виявляти інформаційні викривлення, хоча повністю покладатися на неї без людського втручання поки що не можна.